http://projects.spring.io/spring-data/
Spring Data
Spring Data’s mission is to provide a familiar and consistent, Spring-based programming model for data access while still retaining the special traits of the underlying data store. It makes it easy to use data access technologies, relational and non-rela
spring.io
ORM object relation mapping
ORM은 자바 객체와 SQL DB의 테이블 사이의 맵핑 메타데이터를 사용하여
자바 객체를 SQL DB의 테이블에 자동으로 영속화해주는 기술
객체를 릴레이션 테이블에 맵핑할 때 생기는 문제
- 밀도 granularity 문제 : 객체는 다양한 크기의 다양한 커스텀 객체를 만들기 쉬우나 릴레이션은 기본 타입만 사용할 수 있다.
- 서브타입 subtype 문제 : 객체는 상속 구조를 만들기 쉽지만 릴레이션은 그렇지 못한다
- 식별성 identity 문제 : 객체를 동일한 객체로 인식할때 레퍼런스가 같은면 동일하다고 할지, 레퍼런스가 달라도 가지고 있는 멤버와 그 값이 동일할 때 같다고 할지에 대해서 정해줘야 하지만 릴레이션에서는 주키를 같으면 동일한 인스턴스로 본다.
- 관계 association 문제 : 객체는 방향성이 존재하고 다대다 맵핑이 가능하지만 릴레이션은 방향성이 존재하지 않고 외래키로 관계를 표현할 뿐이다.
- 데이터 네비게이션 navigation 문제 : 객체는 콜렉션을 순회하고 레퍼런스를 이용해 다른 객체로 이동도 가능하지만
릴레이션은 데이터베이스에 성능을 위해 적은 요청으로 여러 릴레이션에 접근하기 위해 join을 사용해야한다.
스프링 데이터
- 스프링 데이터 : SQL, NoSQL 저장소 지원
- 스프링 데이터 common : 여러 저장소 지원 프로젝트의 공통 기능 ( Repository > CrudRepository > PagingAndSortingRepository )
- 스프링 데이터 rest : 저장소의 데이터를 하이퍼미디어 기반 HTTP리소스로 제공
- 스프링 데이터 JPA : 스프링데이터 common이 제공하는 기능에 JPA 관련 기능 추가 ( JpaRepository )
JPA 실습
new Spring Starter Project
DI
spring data JPA
lombok
spring boot devTools
oracle JDBC
(JDBC API)
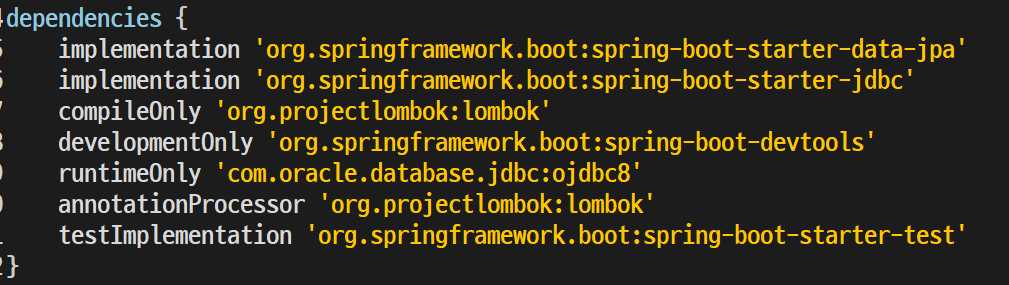
application.properties
Generic Editor로 열면 content assist 사용가능

spring.datasource.url=jdbc:oracle:thin:@111.111.111.11:1521:xe
spring.datasource.username=j
spring.datasource.password=j
#테이블 자동 생성 옵션
spring.jpa.hibernate.ddl-auto=create
JPA는 구현체로 Hibernate를 사용한다.
#시작시 drop테이블시 error가 발생하면 멈춤
spring.sql.init.continue-on-error=false
ddl create 작업 실행시 drop 후 create를 하는데 최초에는 table이 없기 때문에 drop시 오류가 발생하고 실행을 멈추는데
실행이 멈추는 걸 막고 계속 실행하게 하는 설정
#JPA sql 초기화 작업 user-insert.sql을 테이블이 drop-create 이후 자동으로 실행시켜줌
spring.sql.init.mode=always
spring.sql.init.data-locations=classpath:user-insert.sql,classpath:guest-insert.sql
#spring.sql.init.schema-locations=classpath:user.ddl
spring.sql.init 은 sql이 시작될때 바로 실행되는 작업을 뜻한다.
나중에 테스트를 위해 sql insert 작업을 할 때
insert.sql 파일로 다량의 sql 작업을 처리할 때 data-locations에 insert.sql 파일을 알려준다.
sql 시작할때 테이블을 생성할 ddl 파일을 init으로 실행하기 위한 설정으로 schema-locations에 ddl 파일의 위치를 기술
여기서는 hibernate.ddl-auto=true 설정을 하여 생략하였다.
spring.jpa.defer-datasource-initialization=truetrue로 설정해서 hibernate 초기화 이후 data.sql가 실행되도록 변경한다.
hibernate 초기화 이후 sql이 실행되도록 지연시키는 설정
spring 실행 로그

#SQL을 로그로 보여주는 옵션, 상세보기 옵션
spring.jpa.show-sql=true
spring.jpa.properties.hibernate.format_sql=true

logging.level.org.hibernate.orm.jdbc.bind=trace


쿼리에 binding 하는 파라메터를 보여줌
entity 패키지 하위 UserEntity 클래스 생성
entity는 객체세상에서 table을 표현하는 이름으로 entity의 이름은 default로 클래스의 이름(소문자)로 설정되고 name property로 지정해 줄 수 있다.
table은 Relation에서의 table 이름으로 대부분의 DB에서는 user를 예약어로 사용하므로 user를 사용하지 못한다.
@Id
private String userid;
PK 컬럼으로 할 멤버필드에는 @Id 어노테이션을 붙인다.
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "guest_guest_no_seq")
@SequenceGenerator(name = "guest_guest_no_seq", sequenceName = "guest_guest_no_seq", initialValue = 1, allocationSize = 1)
@GeneratedValue() 시퀀스 같이 데이터를 자동으로 생성해준다.
@SequenceGenerator(name="", sequenceName="", ...)
sequenceName은 실제로 생성되는 물리적인 seq의 이름이고 name은 개발자가 sequence에 붙여준 이름으로
GeneratedValue에 generator 이름은 @Generator 의 name을 입력한다.
@Entity(name="user")
@Table(name="userinfo")
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class User {
@Id
private String userId;
private String password;
private String name;
private String email;
}
이렇게 설정하고 실행시키면 userinfo 테이블이 생성된다.
#테이블 자동 생성 옵션
spring.jpa.hibernate.ddl-auto=create

userId 카멜케이스로 하면 JPA는 테이블에 스네이크케이스로 바꿔준다.
private String userid;
private String password;
private String name;
private String email;
userid로 하면 테이블에

userid 로 컬럼명이 설정된다.
컬럼명을 명시해주고 싶을 땐 @Column(name="") 어노테이션을 사용
@Column(name="useridTest")
@Id
private String userid;

++
만약 user_id라고 스네이크 케이스로 객체의 멤버변수명을 설정하면
나중에 JPA에서 쿼리를 날릴때 문제가 생길 수 있으므로 사용을 지양한다.
@Column 어노테이션을 컬럼에 length, nuallable, constraints 등을 설정할 수 있다.
@Column(length = 10, nullable = false)

@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "guest_guest_no_seq")
@SequenceGenerator(name = "guest_guest_no_seq", sequenceName = "guest_guest_no_seq", initialValue = 1, allocationSize = 1)
@Id
private Long guestNo;//wrapper객체로 쓰는게 좋고 Integer보단 long
JPA를 사용할 땐 가급적 기본형보단 WrapperClass를 사용해주는게 좋은데
자릿수가 짧은 Integer보단 Long을 사용하는 것이 좋다.
@ColumnDefault("sysdate")
private Date guestDate;
컬럼에 default 값을 설정해줄때는
@ColumnDefault 어노테이션을 사용한다.
또는 Column에 columnDefinition에 ddl에 작성하는 columnDefinition부분을 작성하면 된다.

DATE DEFAULT SYSDATE
@Column(columnDefinition = "date default sysdate")
private Date guestDate;
repository 인터페이스 생성
Jpa를 사용하기 위해 JpaRepository<entity,idtype> 상속extends
JpaRepository는 CrudRepository를 상속하고
CrudRepository는
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
...
등 비즈니스에 필요한 다양한 메소드들이 있다.
Repository test하기
repository에서 new- JUnit Test Case 생성
TestCase를 생성하면 Repository에서 상속한 인터페이스와 그 상위 인터페이스들의 메소드들을 테스트 할 수 있다.
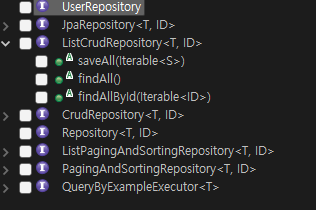
테스트할 클래스에 @SpringBootTest 어노테이션을 붙여주거나
SpringJpaApplicationTests를 상속받아 SpringJpaApplicationTests의 @SpringBootTest도 상속받아 쓴다.

@DisplayName("회원아이디로 찾기")
@Test
@Disabled
void testFindById() {
Optional<User> optionalUser = userRepository.findById("guard1");
// optional객체는 null일 수 없다.
if (optionalUser.isPresent()) {
User findUser1 = optionalUser.get();
System.out.println(findUser1);
}
}
JPA에서 기본 쿼리가 아닌 쿼리가 필요할 때에도 SQL문을 작성할 필요가 없다.(물론 직접 작성해줄 수도 있다.)
JPA는 method Interceptor로 메소드의 호출시 method를 가로채 메소드의 이름으로 필요한 쿼리를 작성해 구현해준다.
그래서 우리가 어떤 쿼리가 필요하면 그에 맞게 이름을 지어줘야한다.
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods.query-creation
Spring Data JPA - Reference Documentation
Example 121. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
메소드 이름 짓는 방법은 위 문서에 나와있다.
List<User> findByName(String name);
List<User> findByNameAndEmail(String name,String email);
List<User> findFirst2ByName(String name);
List<User> findTop2ByName(String name);
List<User> findByNameContains(String name);
List<User> findByNameStartingWith(String name);
List<User> findByNameLike(String name);
System.out.println(">>>findByNameLike :"+userRepository.findByNameLike("%경호%").size());


리턴 타입으로는
void, 기본형, Wrapper, T(Object), Optional<T>, List<T>, Stream<T>, Iterator<T>, Collection<T>, Page<T>, Slice<T> ...
메소드의 이름은
find, get, search, read, stream, query, count... 으로 시작하고
find(_찾을객체_)By_조건 형식으로 한다.
@Query 어노테이션 : 쿼리를 직접 작성할 때
@Query(value="select * from userinfo where name=?1",nativeQuery = true)
List<User> findByNameSQL(String name);
nativeQuery는 JPQL이 아닌 SQL문을 그대로 작성할 때 사용한다.
select * from userinfo where name=?1에서
?1은 매개변수 순서를 나타낸다.
?1 자리에 첫번째 매개변수인 String name이 들어간다는 뜻이다.
@Test
@DisplayName("방명록저장")
void save() {
Guest guest = Guest.builder().guestName("name").guestEmail("email").guestHomepage("home").guestContent("content").guestTitle("title").build();
System.out.println(guestRepository.save(guest));
System.out.println(guest);
}

guest와 save한 후 반환되는 guest는 같은 객체이다
guest에 save해서 pk가 생성되었을때 guest에도 pk가 set된다.
*@ColumnDefault("sysdate")로 디폴트 값을 설정해주었는데 guestDate=null 값이다..
hibernate에서 제공하는 @CreationTimestamp 어노테이션을 사용하면 된다.
@Column(columnDefinition = "date default sysdate")
@CreationTimestamp// insert시 자동으로 값을 채워줌
private Date guestDate;
@Test
@DisplayName("방명록수정")
void update() {
Guest guest = guestRepository.findById(1L).get();
System.out.println("Guest 1L : "+guest);
guest.setGuestContent("내용");
guest.setGuestName("이름");
guestRepository.save(guest);
System.out.println("Guest 1L update: "+guest);
}
guest의 pk 타입은 Long 이기 때문에 1에 L을 붙여준다.
업데이트
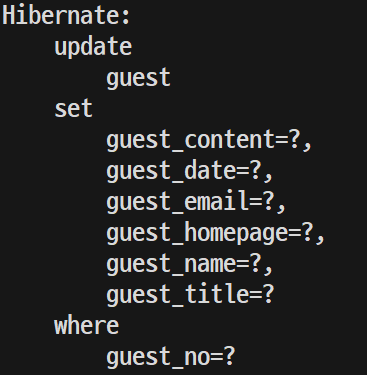
guest update를 하는데 내용과 이름만 바꿨는데 쿼리는 모든것을 수정하고 있다.
이는 성능에도 영향을 주기 때문에 수정이 필요한부분만 수정하는 쿼리를 만들도록 해준다.
@DynamicUpdate
public class Guest {
guest에 @DynamicUpdate 어노테이션을 추가한다.
한번에 여러 인스턴스를 업데이트하는 방법
List<Guest> list =guestRepository.findByGuestNoBetween(1L, 5L);
for (int i = 0; i < list.size(); i++) {
list.get(i).setGuestName("nameChange");
}
guestRepository.saveAll(list);
saveAll()로 list를 모두 save 할 수 있다.





