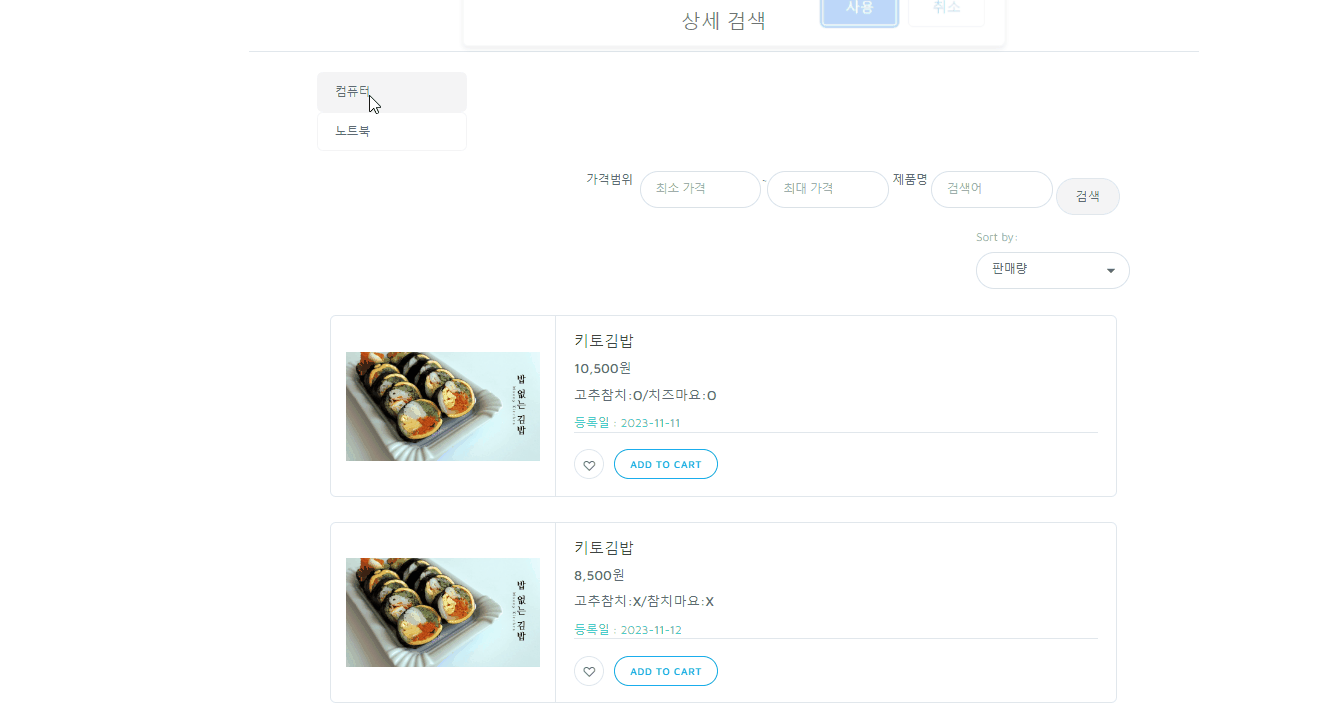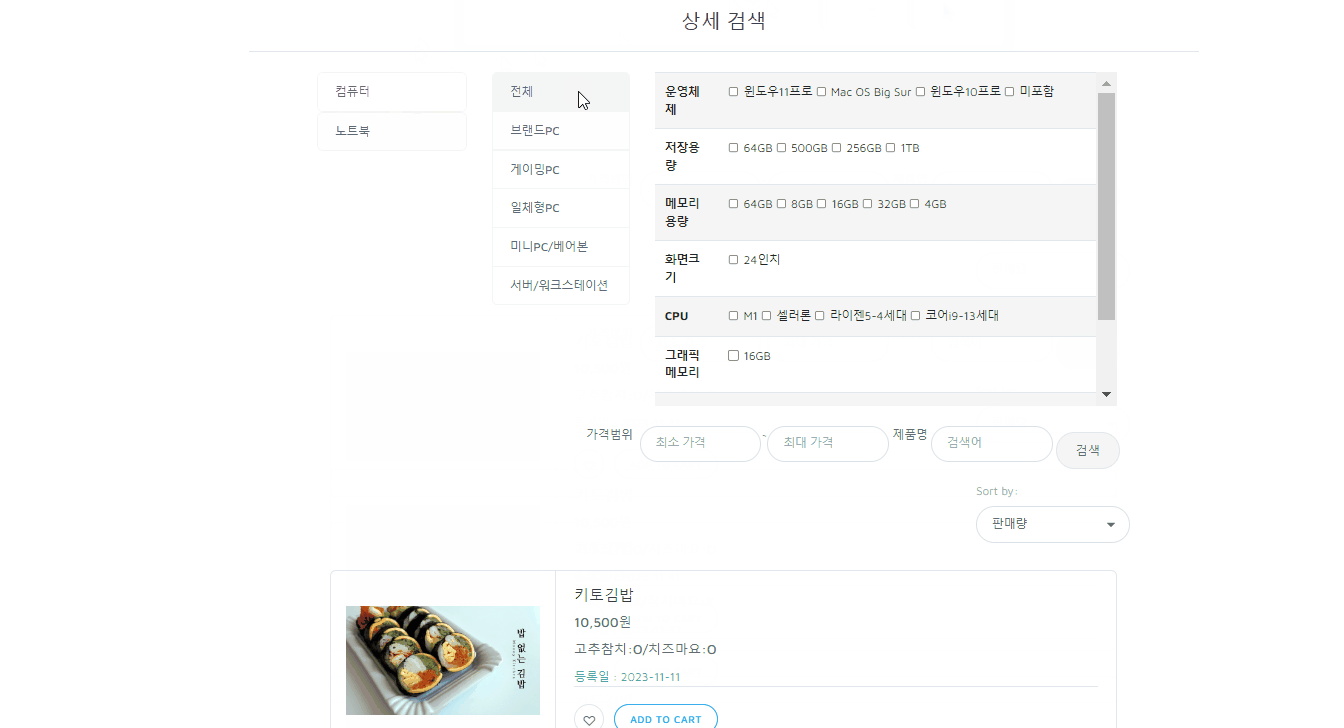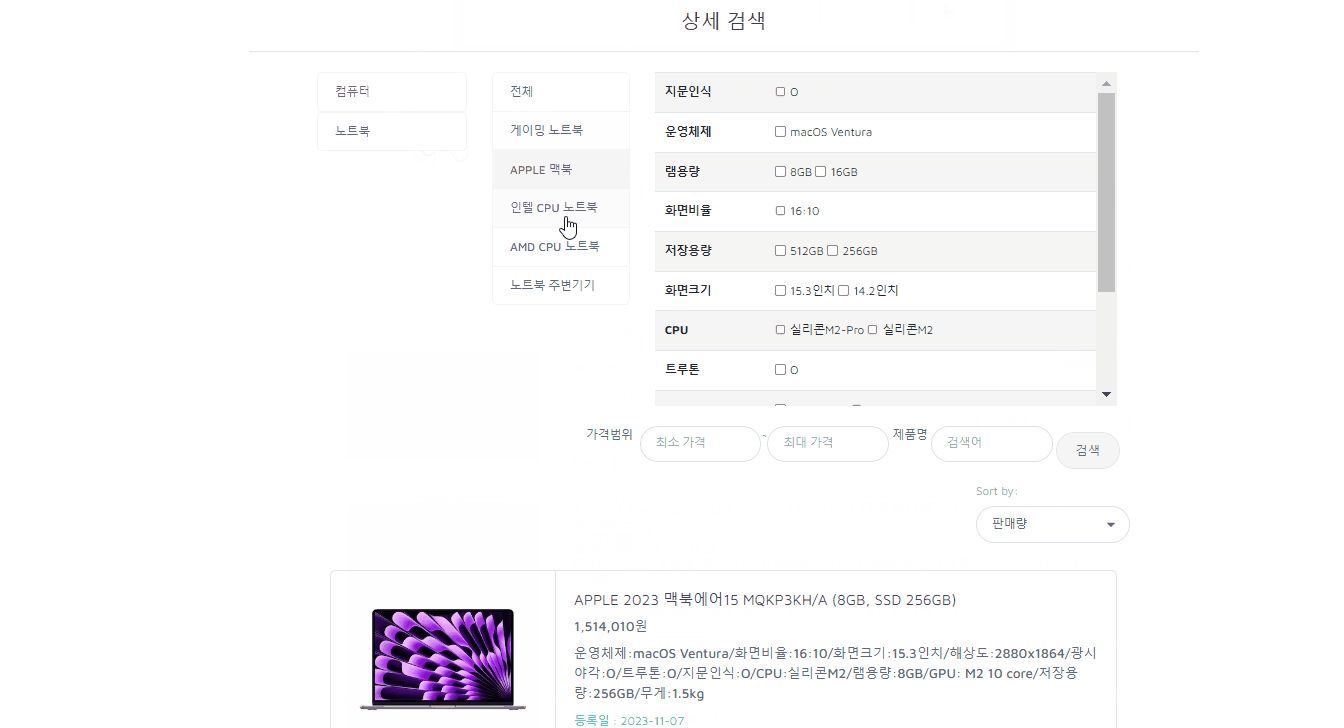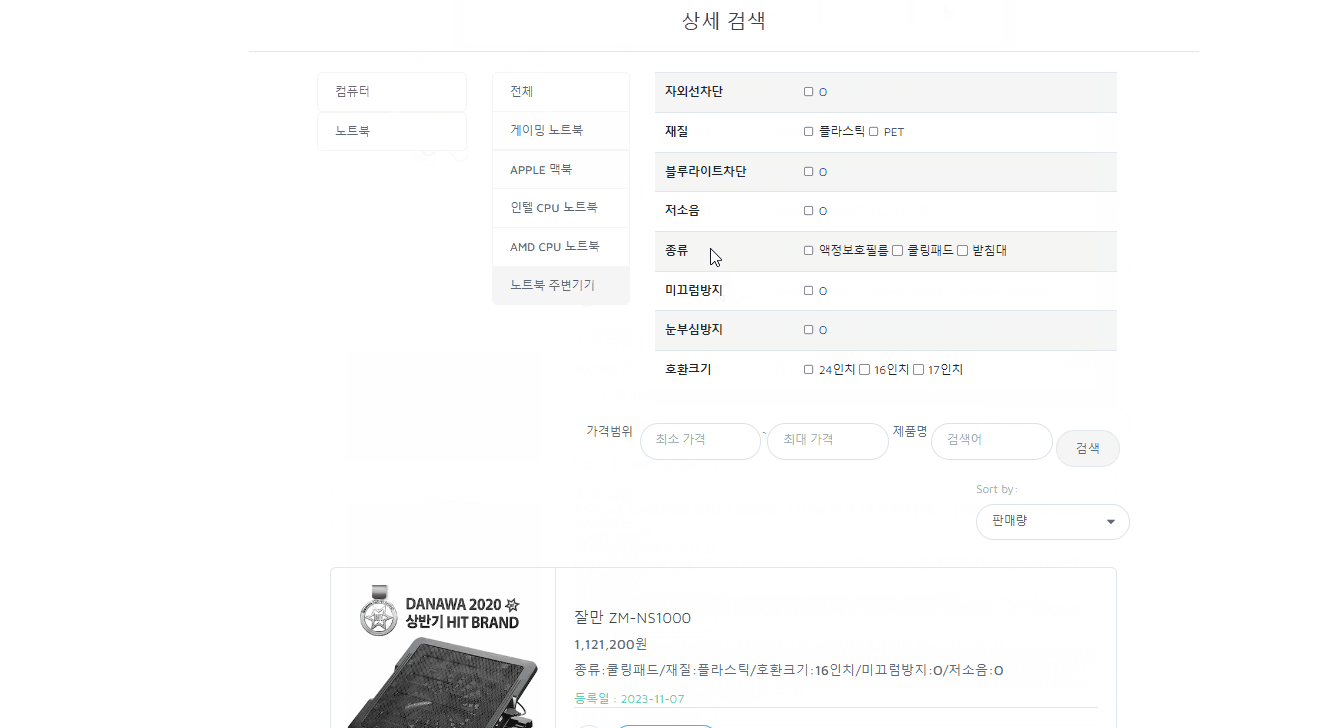
Tool : ERDCloud
ERDCloud
Draw ERD with your team members. All states are shared in real time. And it's FREE. Database modeling tool.
www.erdcloud.com

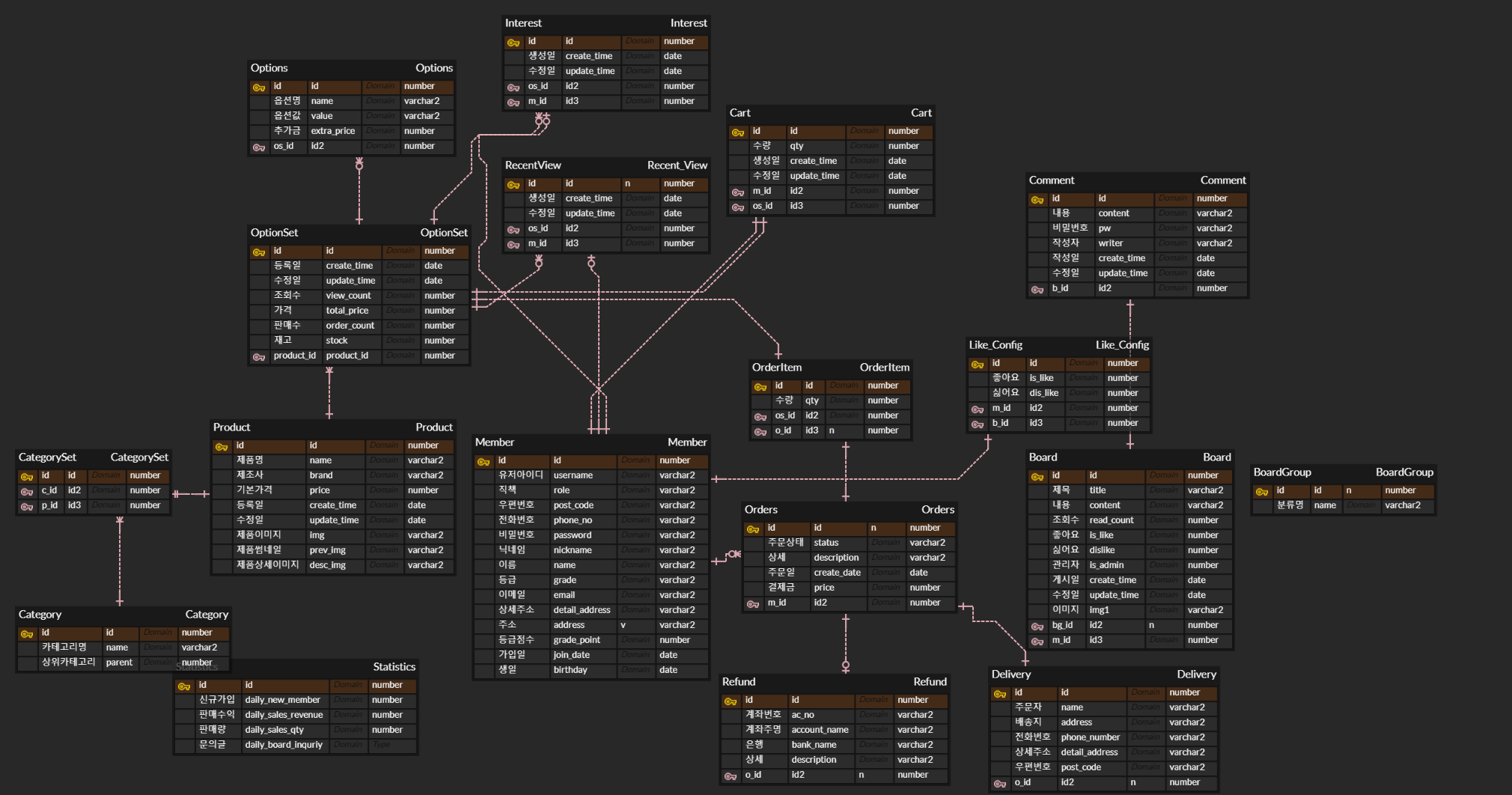
프로젝트 전체 테이블

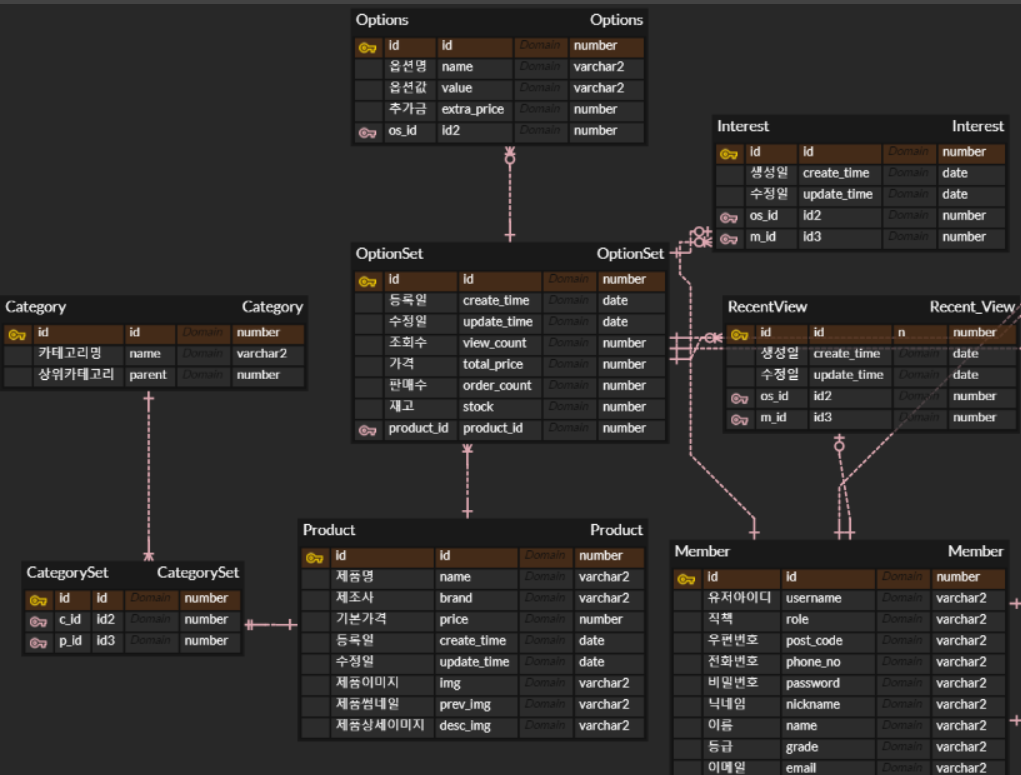
프로덕트 관련 테이블
Product 테이블 : 제품의 기본 모델에 관한 정보를 담은 테이블
Option 테이블 : 제품이 가질 수 있는 옵션의 정보를 담은 테이블
OptionSet 테이블 : 제품에 옵션들의 정보를 포함하여 하나의 상품으로 간주되어 카트와 주문에 포함될 테이블
Category 테이블 : 카테고리 정보를 담은 테이블
CategorySet 테이블 : 카테고리와 프로덕트를 연결해주는 테이블
Interest, RecentView 테이블 : 관심상품, 최근 본 상품 테이블
-카테고리 테이블
카테고리 테이블은 카테고리 이름, 그리고 카테고리 테이블을 셀프 참조하여 부모 카테고리를 가질 수 있어
계층형으로 구성할 수 있게 하였고
카테고리와 옵션셋 테이블을 다대다 맵핑하여
하나의 옵션셋은 여러개의 카테고리를 가질 수 있게 하였다.
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Entity
public class Category {//셀프 참조하는 오너테이블, 카테고리셋과는 종속테이블
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id; //pk
private String name; //카테고리 이름
@JoinColumn(name="parent", nullable = true)
@ManyToOne
@ToString.Exclude
private Category parent; //부모 카테고리
@OneToMany(mappedBy = "parent")
@Builder.Default
@ToString.Exclude
private List<Category> childTypes= new ArrayList(); //자식 카테고리들
@OneToMany(mappedBy = "category")
@Builder.Default
@ToString.Exclude
private List<CategorySet> categorySets = new ArrayList<>();
//다대다 맵핑을 위한 categorySet과 관계 설정
}
-프로덕트 테이블
public class Product extends BaseEntity {//제품의 기본 모델 정보
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;//pk
private String name;//제품명
private String brand;//브랜드
private Integer price;//기본 가격
private String descImage;//설명 이미지 파일
private String prevImage;//디테일이미지
private String img;//제품 이미지
@OneToMany(mappedBy = "product",fetch = FetchType.EAGER)
@Builder.Default
private List<CategorySet> categorySets = new ArrayList<>();
//하나의 제품은 부모카테고리, 자식카테고리 여러개를 가질 수 있다.
//예를 들어, 컴퓨터, 일체형PC, 브랜드PC ...
@ToString.Exclude
@OneToMany(mappedBy = "product",cascade = {CascadeType.REMOVE,CascadeType.PERSIST},orphanRemoval = true)
@Builder.Default
private List<OptionSet> optionSets = new ArrayList<>();
}
여기서 Product가 상속받은 BaseEntity는 createTime과 updateTime을 가진 엔터티로
@MappedSuperclass
public class BaseEntity {
@CreationTimestamp
@Column(updatable = false)
@ToString.Exclude
private LocalDateTime createTime;//데이터 생성시간
@UpdateTimestamp
private LocalDateTime updateTime;//데이터 갱신시간
}
데이터의 관리를 위해 필요한 기본적인 정보를 가지는 superclass로 다른 엔터티들이 상속받아 사용할 수 있게
@MappedSuperclass 어노테이션을 사용해 테이블로 생성되지 않고 상속하는 역할만 할 수 있게 하였다.
프로덕트는 제품의 기본 모델에 관한 정보를 담은 테이블로 제조사, 제품 이미지, 기본 가격 등에 관한 정보를 담고 있다.
프로덕트 테이블에 대해 고민을 많이 했는데
컴퓨터와 같이 하나의 모델에 대해서도 다양한 옵션이 선택될 수 있고 선택된 옵션에 따라 가격이 변동 될 수 있기에
기본 모델을 product로 하고 거기에 options을 더한 optionset을 하나의 완전한 상품으로 구상하였다.
그래서 cart, orderitem, 관심상품, 최근 본 상품 등에 들어갈 제품은 product가 아닌 optionset이 되고,
optionset이 재고, 판매량, 조회수와 같은 정보를 갖게 된다.
실제로 제품 상세 페이지도 product가 아닌 optionset의 상세 페이지가 된다.
public class Options {//옵션셋FK를 가지는 오너테이블
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;//pk
private String name; //옵션명
private String value; //옵션값
private Integer extraPrice;
//해당 옵션이 옵션셋에 등록될 경우 프로덕트의 총 가격에 추가금
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "optionSetId")
@ToString.Exclude
private OptionSet optionSet;//옵션셋 FK
}
여기서 옵션과 옵션셋 테이블을 한번 더 분리한 이유는
컴퓨터만을 product의 대상으로 삼고 있지 않고 다양한 전자제품을 대상으로 하기 때문에
options가 셀 수 없이 많아질 수밖에 없고 만약 optionset에 그 많은 options들을 nullable 컬럼으로 만들어 두는 것은 매우 비효율적이라고 생각했다.
그래서 옵션 설정에 자유도를 높이기 위해 options 테이블을 분리하였다.
옵션셋에 totalPrice를 두는 것에 관해서 많은 고민을 했었다.
원래는 기본 product의 price에 options의 extraPrice들을 모두 더해 나온 값을 표시하면 된다고 생각했는데
제품 리스트를 조회할 때마다
매 상품마다 options를 모두 뽑아 가격 연산하는 과정을 거치는 작업은 올바른 작업은 아니라고 판단하였고
옵션셋에 총가격 컬럼을 하나 추가하는 편이 훨씬 경제적이라고 판단하여
제품을 insert 하는 과정에서 extraPrice들을 모두 더해 optionset의 totalPrice의 컬럼에 값을 대입해주기로 하였다.
- 관심상품, 최근 본 상품
관심상품과 최근 본 상품은 멤버와 옵션셋을 참조키로 가진다. 그리고 최근 본 상품에는 30일 이후 자동으로 삭제되는 서비스를 구현한다.
@Entity
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@EqualsAndHashCode(callSuper = true)
@ToString(callSuper = true)
@Table(name = "interest", uniqueConstraints = @UniqueConstraint(columnNames = {"memberId","optionSetId"}))
public class Interest extends BaseEntity{//관심상품
//유저와 옵션셋을 이어주는 중간테이블
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;//pk
@JoinColumn(name = "memberId")
@ManyToOne
private Member member;// 유저FK
@JoinColumn(name = "optionSetId")
@ManyToOne
@ToString.Exclude
private OptionSet optionSet;// 옵션셋FK
}
관심상품과 최근 본 상품은 멤버와 옵션셋의 복합키로써 유니크 제약조건을 가져야한다.
'Java > Project' 카테고리의 다른 글
| 스프링부트 프로젝트 CI/CD 환경 구축 (with.AWS + GIthub Actions) (0) | 2023.11.24 |
|---|---|
| 스프링부트 프로젝트 서비스와 예외처리 (1) | 2023.11.22 |
| 스프링부트 프로젝트 JPA 활용 (0) | 2023.11.21 |
| 스프링부트 프로젝트 계층에 따른 데이터 전송 형태 (0) | 2023.11.21 |
| 쇼핑몰 웹사이트 제작 프로젝트 (0) | 2023.11.09 |